
Der Einsatz künstlicher Intelligenz (bzw. artificial intelligence) dringt immer stärker in alle Lebensbereiche der Menschen vor. Vielfach trifft bereits ein KI-Modell Entscheidungen, die Menschen in deren täglichem Leben beeinflussen. Beispielhaft sei hier der Prozess der Risikoanalyse bei der Kreditvergabe angeführt. Aufgrund verschiedener Merkmale trifft das KI-Modell im Hintergrund eine Entscheidung, in welche Risikoklasse ein Kreditwerber eingestuft werden sollte.
In solchen sensiblen Bereichen ist es erforderlich, dass wir künstliche Intelligenz nicht mehr rein als ein “Black-Blox-System” betrachten, in das wir Daten einfließen lassen und am anderen Ende ein Ergebnis erhalten, von dem wir nicht wissen, wie es zustande kommt.
Frei nach dem Motto: It’s Magic.
Künstliche Intelligenz ist inzwischen auf einer Stufe im Reifeprozess angelangt, der verlangt, dass auch KI-Modelle in einen Softwareprozess eingebettet werden können. Das bedeutet, auch KI-Modelle müssen testbar und erklärbar sein.
Hinter dem Schlagwort explainable ai steckt die Anforderung, zu wissen bzw. nachvollziehen zu können, wie ein KI-Modell zu einer Entscheidung findet. Welche Features sind besonders ausschlagkräftig und beeinflussen die getroffene Prognose. Wie verändern sich die “internals” des Modells während des Trainings.
Mithilfe solcher Analysen kann auch ein etwaiger bias eines KI-Modells erkannt und beseitigt werden. So verhindern wir, dass die künstliche Intelligenz auf Basis der Trainingsdaten Entscheidungen zugunsten oder gegen eine bestimmte, abgegrenzte Gruppe auf Basis von einigen wenigen Merkmalen trifft. Wird ein solcher Bias nicht erkannt, so besteht die Gefahr, dass das Modell aus seinen Entscheidungen in der Vergangenheit lernt und so eine negative Verstärkungsschleife entsteht. Das heißt, durch die Anwendung des Modells wird der Bias noch weiter verstärkt und die Prognosen des Modells noch weiter verzerrt.
Wir fordern daher von unseren KI-Modellen folgende Eigenschaften:
Hinter Continous Learning steckt die laufende Weiterentwicklung (sprich das weitere Training) unseres Modells aufgrund der gelieferten Prognosen.
Unter Drift Detection verstehen wir eine Analyse, ob der Bias in den Trainingsdaten durch unser Modell soweit verstärkt wird, dass die Prognosefähigkeit unseres Modells abdriftet.
Die Explainability stellt sicher, dass wir verstehen, wie unser KI-Algorithmus zu einer Entscheidung kommt - welche Features der Daten die Prognose des Modells am stärksten beeinflussen.
Wir als Menschen vertrauen bei der Beratung oder bei Entscheidungen ungern maschinellen Prozessen, die wir nicht einmal verstehen können. Nichtsdestotrotz vertrauen wir auf menschliche Experten, ohne dass wir deren Fehlerquote kennen.
Angenommen, wir entwickeln ein Expertensystem auf Basis künstlicher Intelligenz, um medizinische Diagnosen zu erstellen. Das Modell verwendet die Patientenakte, um zu Entscheidungen zu kommen. Wir testen unser KI-Modell gegen das Validierungs- und Testdatenset und erhalten entsprechend gut Werte hinsichtlich der gewünschten Metrik wie etwa die Genauigkeit.
Doch wird unser Modell trotz der präzisen Diagnose wahrscheinlich auf wenig Gegenliebe bei Ärzten stossen. Warum? Weil unser Modell die einfache Frage: “Warum hat dieser Patient ein höheres Risiko an Krankheit XY zu erkranken, als jener?”
Auch wenn der Arzt weiß, dass die Prognose unseres Modells wahrscheinlich richtig sein wird, wird er beim Einsatz unseres Modells zögern. Um eine höhere Akzeptanz erreichen zu können, müssen wir es also zu schaffen, die Entscheidungsprozesse unseres Modells darstellen zu können. “Wie kommt also unser neuronales Netz zu seiner Entscheidung?”
Wir können die Explainability unserer künstlichen Intelligenz auf verschiedenen Stufen darstellen:
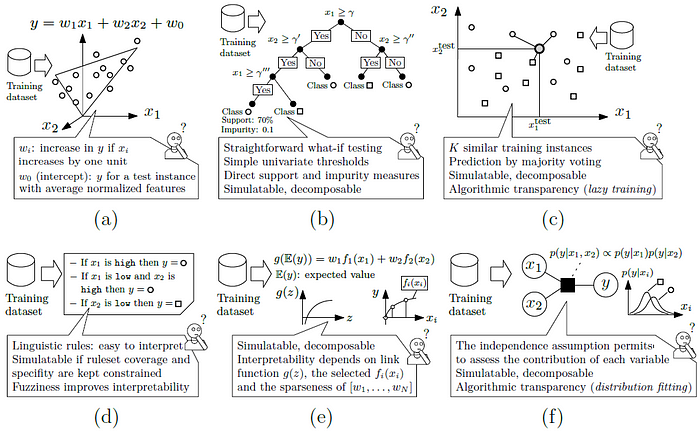
Damit ein KI-Modell direkt erklärbar ist, muss es entsprechend einfach sein. Dafür eigenen sich nur verhältnismäßig einfache Modelle, wie Entscheidungsbäume / decision trees, Linear Modelle, Regelbasierte Systeme unnd Bayes Modelle.
Quelle: https://medium.com/swlh/explaining-explainable-ai-b3ca0f8b357b
Obige Abbildung zeigt verschiedene Algorithmen und deren Level der Erklärbarkeit.
Linear Regression stellt ein einfaches, lineares mathematisches Modell dar. Entscheidungsbäume bzw. Decision Trees sind ein Set von Wenn-Dann-Sonst-Regeln. Auch der KNN - k-nearest neighbours* Algorithmus ist erklärbar, da einfach nur die mittleren Entfernungen aller Punkt für die Berechnung der neuen Gruppen herangezogen wird. Regelbasierte Systeme sind leicht verständlich, da wir es gewohnt sind, mit solchen Systemen zu interagieren. Die gesamt Gesetzgebung ist ein regelbasiertes System. Additive Systeme sind etwas schwieriger zu verstehen, da diese aus zusammengesetzten Funktionen bestehen. Durch Zerlegung (decomposition) könne die komplexen Funktionen in einfache zerlegt werden. Bayes Modelle basieren auf der Wahrscheinlichkeitsrechnung. Jeder mit Verständnis für die Wahrscheinlichkeitsrechnung kann die Regeln nachvollziehen.
Bei der Post hoc Erklärbarkeit gehen wir von dem KI-Modell als Black Box aus. Um den Weg vom Input zum Output verstehen zu können, setzen wir einen weiteren Algorithmus an, der eine sinnvolle Erklärung für die Prozesse innerhalb des Modells liefert. Solche Algorithmen liefern uns vereinfachte Informationen über das Modell, ohne dabei eine größere Unschärfe einzuführen. Eine Möglichkeit besteht darin, aufzuzeigen, welche Features mit welcher Gewichtung in die Prognose des Modells eingehen.
Wir haben also zwei Algorithmen. Einen, der als Black-Box Modell die Daten vom Input zum Output verarbeitet und einen weiteren, der uns eine Analyse dieser Black Box liefert.
Diese Analysealgorithmen können vom Modell unabhängig (agnostic) oder auf das konkrete Modell zugeschnitten (tailored) sein.
Modellunabhängige Algorithmen können mit jedem beliebigen Modell verbundenn werden. Der modellunabhängige Algorithmus soll aus den Prgnosen unseres Modells wertvolle Informationen extrahieren, die Rückschlüssen auf die Wirkungszusammenhänge innerhalb des Modells ermöglichen.
Ein bekannter Vertreter von model agnostic algorithms der eine Erklärung durch Vereinfachung ermöglicht ist LIME (Local Interpretable Model Agnostic Explanations). Durch Permutation der Eingangsdaten versucht dieser Algorithmus herauszufinden, wie sich Änderungen der Inputs auf die Outputs des Modells auswirken.
Die grundlegende Idee dahinter besteht darin, ein Bild in sogenannte Super-Pixel zu zerlegen. Solche Super-Pixel sind Gruppen, benachbarter Pixel, die ähnliche Werte hinsichtlich Helligkeit und Farbspektrum ausbilden. Wenn nun der Wert eines Pixels verändert wird, erwarten wir, dass sich recht wenig an der Prognose ändert.
Diese Gruppen von Super-Pixel ermöglichen es, dem LIME Algorithmus Rückschlüsse auf die Wirkung des Modells zu ziehen, indem strukturiert einzelne Super-Pixel durch Graustufen ersetzt werden und so der Einfluss verschiedener Super-Pixel auf die Gesamtprognose errechnet.
Um die Relevanz von verschiedenen Features zu berechnen stehen uns verschiedene Algorithmen wie SHAP (SHapley Additive exPlanations), QII (Quantitive Input Influence), SA (Sensitive Analysis), ASTRID (Automatic STRucture Identification), etc.
Mithilfe dieser Algorithmen können wir aufzeigen, welche Features den größten Einfluss auf das spätere Ergebnis unseres Modells haben.
Die visuelle Erklärung unseres AI-Modells entspricht im Wesentlichen der Berechnung der Feature-Gewichtung. Dies unterschiedliche Wichtigkeit von Features wird grafisch aufbreitet und kann so einfach interpretiert und verdeutlicht werden.
Gratis-Download
Ehrliche Entscheidungsgrundlage für KMU: Wann sich lokale KI rechnet – mit konkreten Kosten, DSGVO-Einordnung und Umsetzungsfahrplan.
Sie möchten wissen, wie künstliche Intelligenz auch in Ihrem Unternehmen Mehrwert schaffen kann? In einem kostenlosen Erstgespräch besprechen wir Ihre Möglichkeiten.
Oder schreiben Sie uns direkt: [email protected] | +43 660 31 96 763